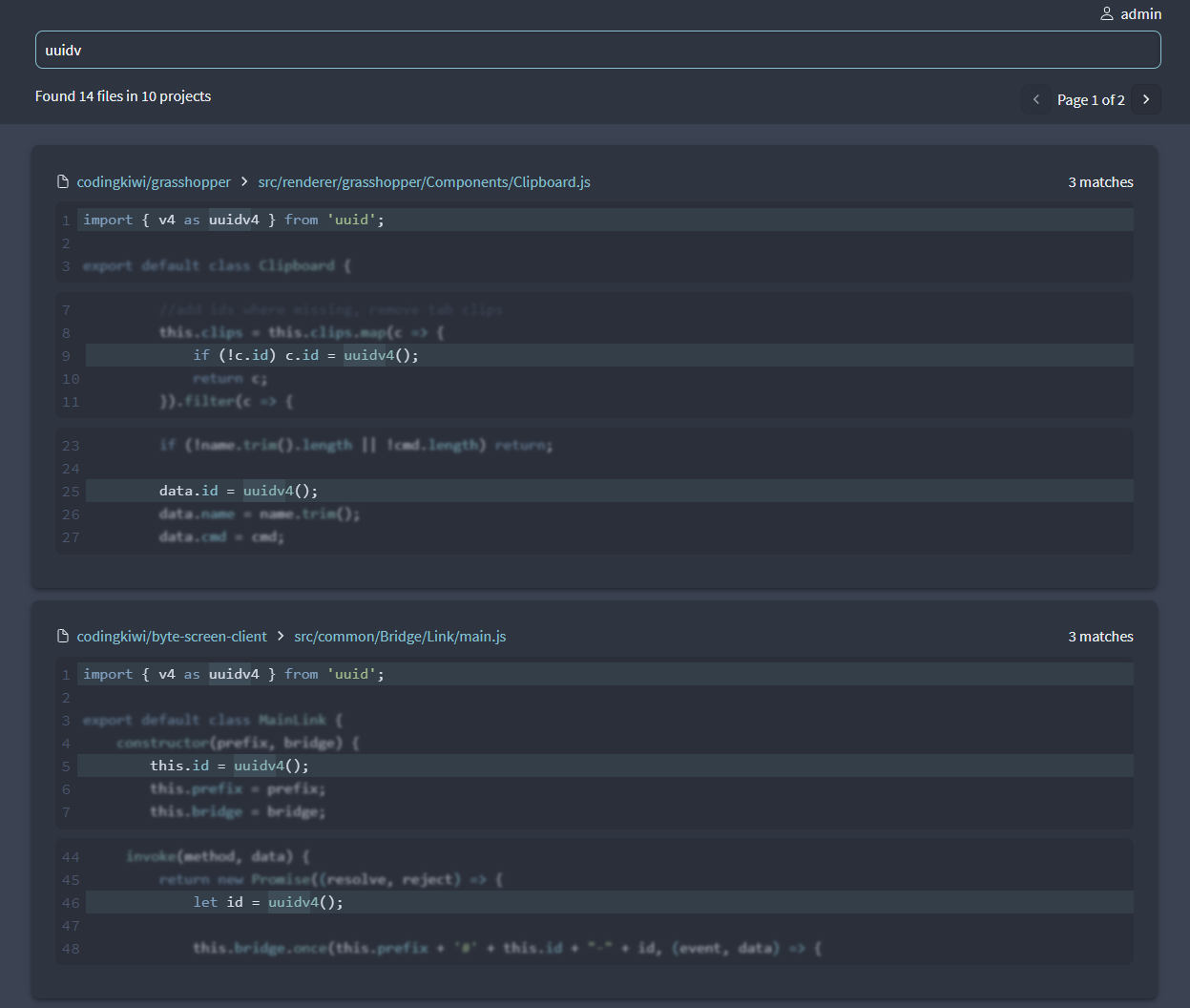
Building a Code Search

I came across the application sourcegraph which is an awesome code search tool that allows you to search across multiple repositories fast (plus a lot of other awesome features).
Under the hood it uses "zoekt", a trigram based search index which was a independent project but is now maintained by sourcegraph itself.
Sourcegraph can be self hosted but it has quite a large footprint (about 20 docker containers). This is okay for big companies that rely on the full featureset. Sourcegraph even list this in their docs:
More specifically, Sourcegraph is great for all developers, except:
- those on smaller teams with a small amount of code
- those that rarely search, read, or review code
So... let's build a code search for smaller teams with a small amount of code! 🎉
Researching
The search index has to go somewhere, I looked around a bit and found meilisearch which seemed very easy to set up and work with, but after reading the docs a bit it became clear that meilisearch is great for searching things like a movie database but not so great for searching through code.
It also does not allow regex searching, it is meant to be used by simple end users that just want to search for a product or movie, with typo-correction.
Sourcegraph is specifically targeted towards developers and by default does exact searches or even regex searching, which works fast thanks to the trigram approach. So I searched for trigram index and read that postgres natively supports it with the extension pg_trgm!
CREATE EXTENSION IF NOT EXISTS pg_trgm;
CREATE INDEX blob_idx ON blobs USING GIN(content gin_trgm_ops);Testing
To have something to test on I ran a script that pulls all my repositories into a folder and throws the file contents into a database table.
I used these two commands for testing the query speed:
;like
EXPLAIN ANALYZE SELECT id from blobs where content LIKE 'test' LIMIT 10
;regex
EXPLAIN ANALYZE SELECT id from blobs where content ~* 'test' LIMIT 10To keep it comparable all queries are executed using pgadmin with explain:
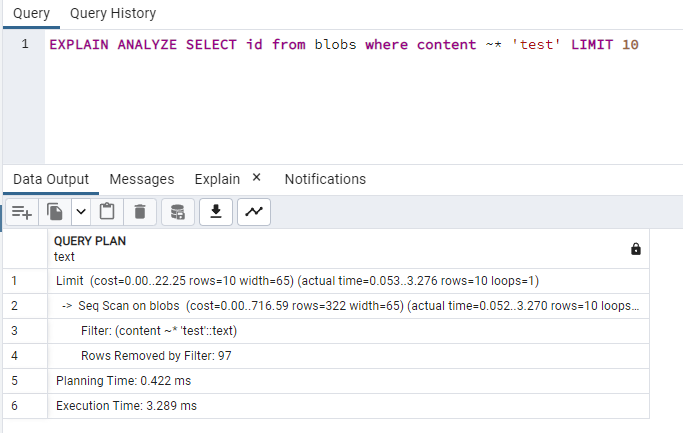
Test results
Initial state, all files in the database:
Rows 6367
DB Size 118 MB
like: 187ms
regex "test": 3ms
regex "uuidv4": 526ms
regex "two words": 843msInterestingly the performance of like was basically the same, no matter what search word I used. The regex query on the other hand was super fast for "test" but super slow for "uuidv4" or "two words"
After creating the trigram index:
Rows 6367
DB Size 147 MB
like: 95ms
regex "test": 3ms
regex "uuidv4": 22ms
regex "two words": 347msAfter ignoring all binary files and all files bigger than 1 MB:
Rows 4071
DB Size 80 MB
like: 11ms
regex "test": 3ms
regex "uuidv4": 0.2ms
regex "two words": 9msJust out of curiosity I also tried out a different approach, instead of having one row per file, I scan each line of each file and save each non-empty unique line into the database. There are no real advantages though, the db size is almost 5 time as high but the query time did not increase as much as I expected.
(It also took my shitty script over an hour to write the stuff to the database)
Final queries
In the final application we need more than the blob id though, we want the project the match appeared in, the file path, the branch and how many matches are in the file
;like
EXPLAIN ANALYZE SELECT projects.name as project_name, project_id, projects.source_id, blob_id, branch, path, ((length(content) - length(replace(content, 'test', '')))::int / length('test')) as matches FROM blobs
JOIN files ON files.blob_id = blobs.id
JOIN projects ON files.project_id = projects.id
WHERE content ~~ 'test'
ORDER BY matches DESC
LIMIT 10 OFFSET 0
13ms
;regex
EXPLAIN ANALYZE SELECT projects.name as project_name, project_id, projects.source_id, blob_id, branch, path, (select count(*) from regexp_matches(content, 'test', 'g'))::int as matches FROM blobs
JOIN files ON files.blob_id = blobs.id
JOIN projects ON files.project_id = projects.id
WHERE content ~ 'test'
ORDER BY matches DESC
LIMIT 10 OFFSET 0
70msWhat impacts the query performance the most is the ORDER BY call in the regex mode, without ordering it only takes 8ms but ordering by most matches is somewhat important and 70ms are still acceptably fast for now
After the query returns all files with matches the search code fetches all necessary blob contents and looks for the pattern in the contents to get the lines and positions of the matches inside the file, this allows the frontend to nicely visualize the matches: